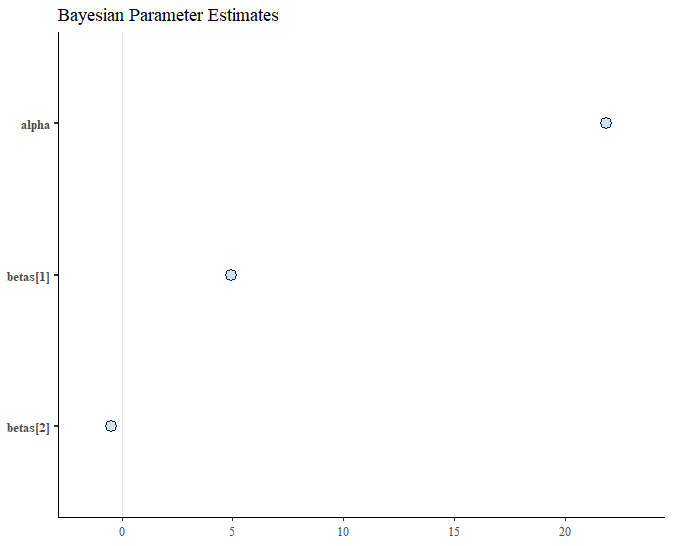
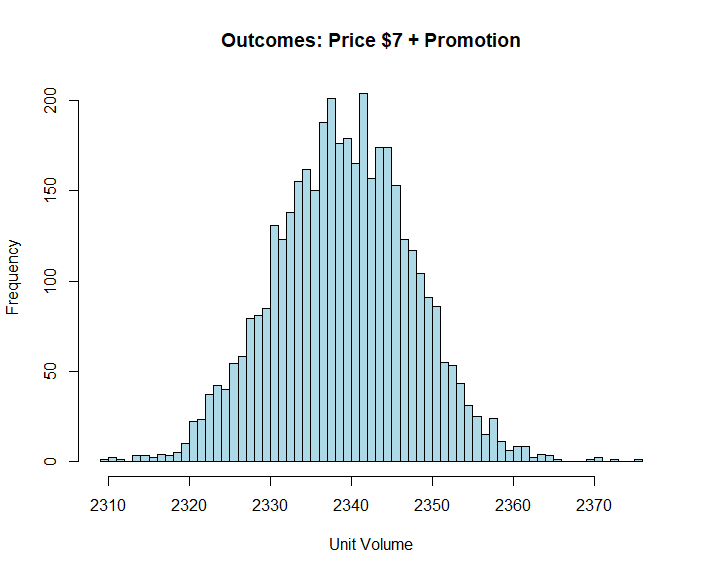
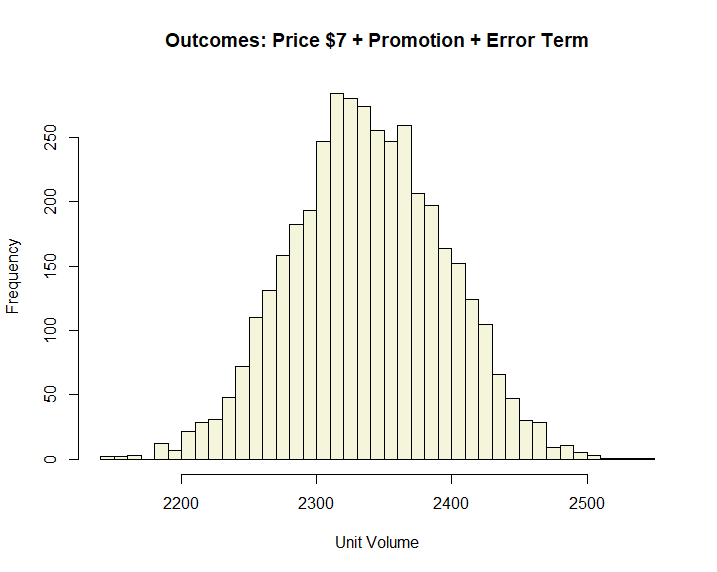
Bayesian Probability
Since our focus is primarily on business intelligence we try to avoid formulas, but it is difficult to understand what Stan is doing without at least touching on probability.
Bayes Rule famously states that the probability of(A) being true given some observed evidence (B) can be described by the following relationship.
P(A|B) = {P(B|A)P(A) \over P(B)}
This formula describes a way to update our beliefs based on evidence. For example, if we believe 50% of customers love our product, but a survey finds only 1 in 1,000 people like the product, then we would be forced to revise our beliefs with respect customer satisfaction downward.
Formula Components
The top line P(B|A) is the likelihood of seeing our observed data (evidence) given that A is true, and multiplied by our prior guess P(A) of the data generating distribution. Together, this gives us an “un-normalized” estimate of P(A|B) which is again the probability of A (a customer loving our product) given some observed evidence (the survey).
This initial estimate P(B|A)P(A) is said to be proportional to the left hand side but it isn’t useful unless we normalize it to a value between [0,1] were a probability should reside. That is until we divide it by P(B) the marginal probability. This is a thorny problem because there is often no mathematical solution to determine P(B).
Markov Chain Monte Carlo
This is where Markov Chain Monte Carlo (MCMC) comes to the rescue. As it turns out, if we take a lot of samples over the proportional version of the parameter space we can get a very good approximation of P(B) which allows us to do the division and get an answer for P(A|B) which is called the posterior probability.
Not only does this assist us in estimating the data generating mechanism, the same samples that helped us solve P(B) can be used to assess uncertainty in our estimates or provide ranges of possible outcomes.
Stan Language
Stan is at the cutting edge of MCMC samplers. It uses a type of sampling known as Hamiltonian MCMC which emulates a frictionless particle exploring the probability space. In more practical terms, it is much faster than previous incarnations of MCMC, easier to work with, and under active development.
We can also a lot with very little code. The example below demonstrates a linear regression model that takes a vector of response variables and a matrix of coefficients as data.
Stan Model File
The easiest way to create a Stan file is to select New->Stan File in R Studio. However, any text file is fine, provided it is saved with a “.stan” extension R Studio will recognize it.
As an aside, we need to ensure there is one blank line at the end of the file or a warning will trigger saying the file is incomplete. This doesn’t affect the compiler but it is a bit annoying.