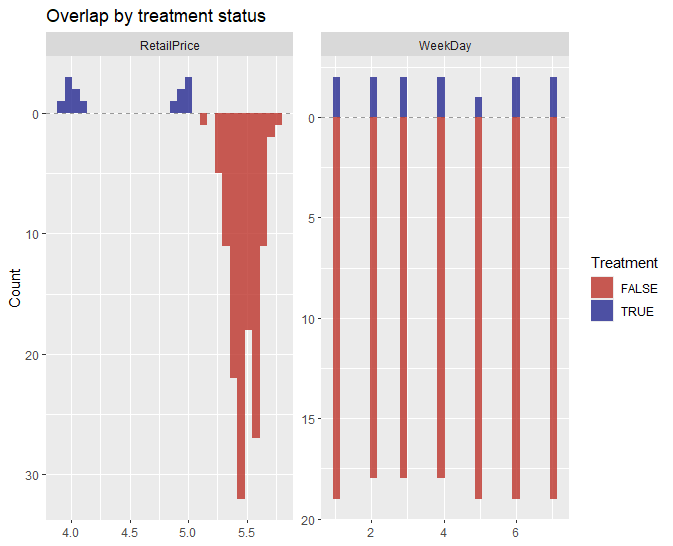
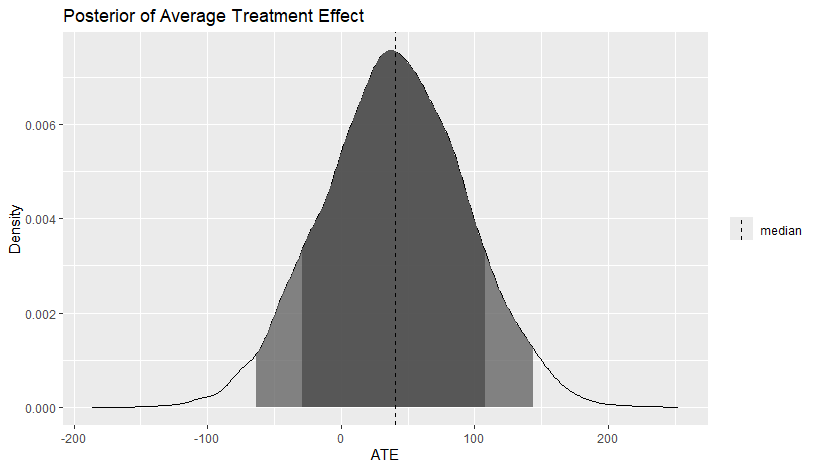
SalesData <- structure(list(TrsDate = 1:143, Sales = c(247.05, 278.99, 362.34,
384.3, 477.63, 345.87, 274.5, 296.46, 334.89, 400.77, 521.55,
351.36, 203.13, 197.64, 230.58, 263.52, 362.34, 334.89, 466.65,
219.6, 247.05, 258.03, 290.97, 290.97, 527.04, 389.79, 334.89,
241.56, 201.15, 299.97, 312.93, 329.4, 296.46, 274.5, 367.83,
206.62, 247.05, 340.38, 461.16, 329.4, 285.48, 274.5, 225.09,
170.19, 225.09, 340.38, 340.38, 186.66, 285.48, 340.38, 296.46,
323.91, 428.22, 192.15, 334.89, 334.89, 269.01, 284.98, 351.36,
400.77, 318.42, 219.6, 263.52, 257.05, 323.91, 312.93, 488.61,
271.51, 329.4, 263.52, 269.01, 318.42, 274.5, 307.44, 378.81,
318.42, 269.01, 251.04, 258.03, 323.91, 422.73, 296.46, 263.52,
285.48, 334.89, 356.85, 356.85, 505.08, 312.93, 266.26, 279.99,
274.5, 345.87, 323.91, 378.7, 384.3, 307.44, 285.48, 285.48,
345.87, 329.4, 502.08, 389.79, 312.93, 230.58, 306.94, 312.93,
285.48, 285.48, 345.37, 312.93, 258.03, 236.07, 236.07, 263.52,
285.48, 299.46, 76.86, 98.82, 263.87, 424.55, 474.45, 524.35,
454.49, 374.65, 451.48, 458.98, 405.49, 510.95, 428.94, 447.45,
403.45, 251.05, 274.5, 323.91, 340.38, 296.46, 323.91, 269.01,
258.03, 274.5, 181.17, 219.6), RetailPrice = c(5.48, 5.6, 5.58,
5.56, 5.64, 5.62, 5.45, 5.23, 5.36, 5.28, 5.49, 5.47, 5.52, 5.4,
5.45, 5.56, 5.45, 5.43, 5.58, 5.52, 5.49, 5.56, 5.44, 5.56, 5.45,
5.51, 5.41, 5.31, 5.71, 5.48, 5.59, 5.56, 5.46, 5.39, 5.55, 5.31,
5.73, 5.37, 5.41, 5.41, 5.48, 5.5, 5.56, 5.32, 5.57, 5.55, 5.44,
5.35, 5.43, 5.39, 5.5, 5.41, 5.41, 5.54, 5.4, 5.54, 5.34, 5.55,
5.31, 5.37, 5.58, 5.52, 5.66, 5.53, 5.44, 5.61, 5.39, 5.49, 5.56,
5.5, 5.38, 5.48, 5.64, 5.55, 5.39, 5.43, 5.64, 5.67, 5.23, 5.64,
5.16, 5.58, 5.35, 5.63, 5.27, 5.49, 5.35, 5.64, 5.44, 5.45, 5.48,
5.37, 5.53, 5.58, 5.51, 5.57, 5.47, 5.44, 5.36, 5.27, 5.48, 5.33,
5.46, 5.42, 5.52, 5.41, 5.66, 5.44, 5.42, 5.55, 5.4, 5.62, 5.3,
5.41, 5.42, 5.58, 5.61, 5.43, 5.43, 5.01, 4.97, 5.02, 5.03, 4.91,
4.85, 3.95, 4.04, 4.13, 3.91, 4.04, 3.96, 3.97, 5.54, 5.55, 5.44,
5.77, 5.58, 5.44, 5.47, 5.41, 5.34, 5.59, 5.38), WeekDay = c(5L,
6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L,
1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L,
3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L,
5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L,
7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L,
2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L,
4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L,
6L, 7L, 1L, 2L, 3L, 4L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L,
2L, 3L, 4L, 5L, 6L, 7L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 1L), Promo = c(0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)), row.names = c(NA,
-143L), class = "data.frame")