options(scipen = 999)
library(tidyverse)
library(bnlearn)
library(Rgraphviz)
## Simulate Data
set.seed(123)
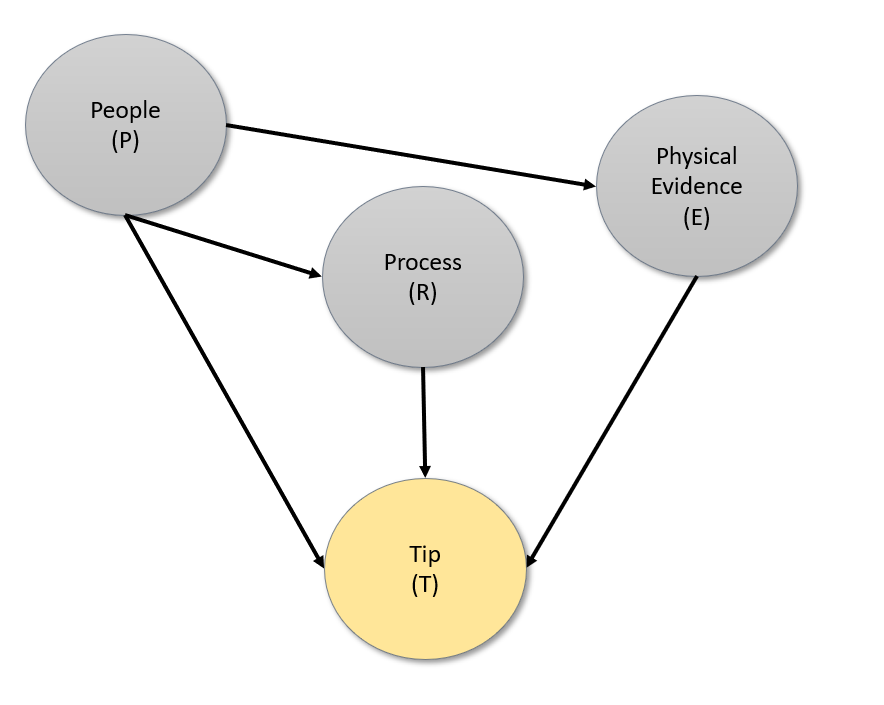
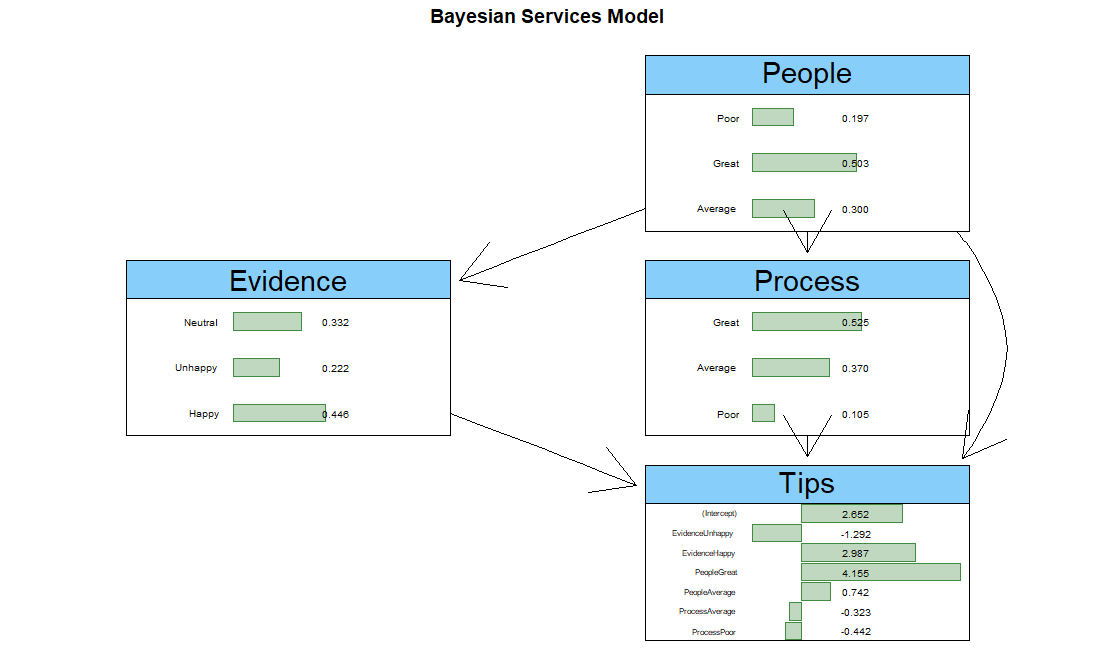
Tips <- rt(1000,5) * 5 + 5 # Random T variable with scale = 5 and location = $5
Tips <- data.frame(Tips = round(ifelse(Tips < 0, 0, Tips),2))
Service <- function(People) {
case_when(
People == "Great" ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.7, 0.2, 0.1)),
People == "Average" ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.1, 0.7, 0.1)),
People == "Poor" ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.7, 0.2, 0.1)),
)
}
Tips <- rowwise(Tips) %>% mutate(
Evidence = factor(case_when(
Tips == 0 ~ sample(c("Happy", "Neutral", "Unhappy"), 1, prob = c(0.1, 0.1, 0.8)),
Tips > 0 & Tips <= 5 ~ sample(c("Happy", "Neutral", "Unhappy"), 1, prob = c(0.1, 0.8, 0.1)),
Tips > 5 ~ sample(c("Happy", "Neutral", "Unhappy"), 1, prob = c(0.8, 0.1, 0.1)),
)),
People = factor(case_when(
Tips == 0 ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.1, 0.1, 0.8)),
Tips > 0 & Tips <= 5 ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.1, 0.8, 0.1)),
Tips > 5 ~ sample(c("Great", "Average", "Poor"), 1, prob = c(0.8, 0.1, 0.1)),
))) %>% mutate(Process = factor(Service(People))) %>% ungroup() %>% as.data.frame()