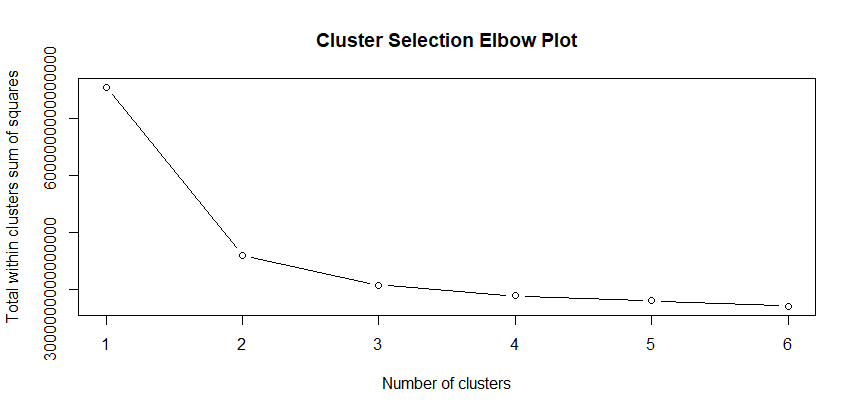
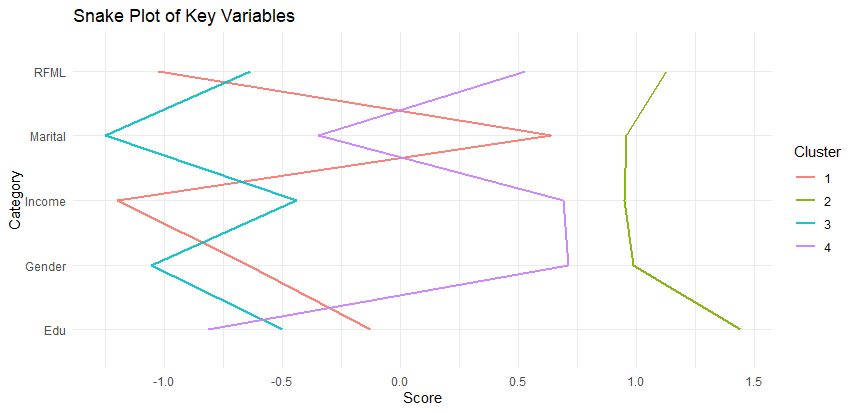
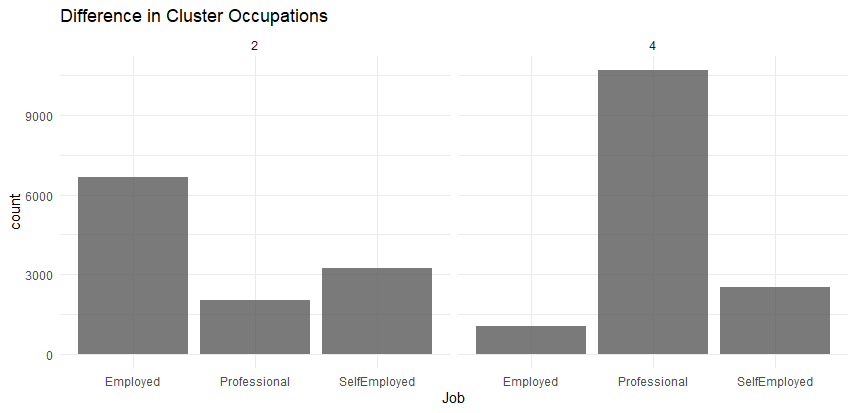
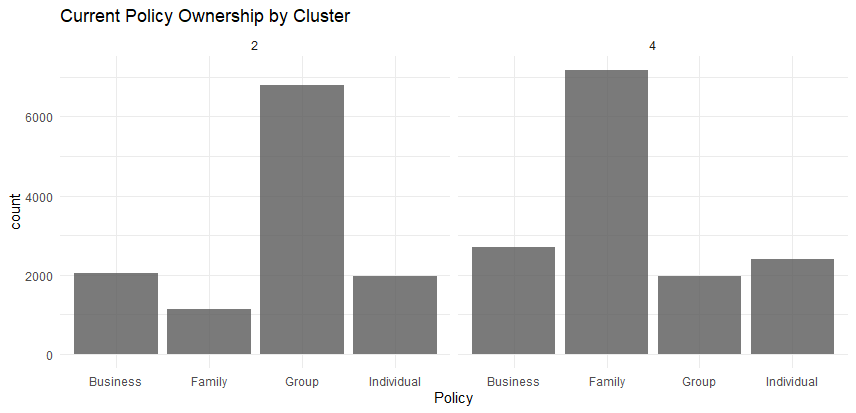
## Clean up SegData
ClusterData <- dplyr::select(SegData,
Customer.ID, Age, Gender, Marital.Status, Education.Level, Occupation, Income.Level,
Purchase.History, Preferred.Communication.Channel, Preferred.Language, Policy.Type,
Insurance.Products.Owned, Coverage.Amount, Premium.Amount, Geographic.Information
)
colnames(ClusterData) <- c("ID", "Age", "Gender", "Marital", "Edu", "Job","Income", "LastPurchase", "ComPref", "Lang",
"Policy", "Owned", "Cover", "Prem", "Geo")
ClusterData$LastPurchase <- mdy(ClusterData$LastPurchase)
ClusterData$LastPurchase <- as.numeric(difftime(ymd("2023-12-28"), ClusterData$LastPurchase, units = "days"))
ClusterData <- mutate(ClusterData,
ComPref = factor(ComPref, levels = c("Mail", "Email", "Text", "Phone", "In-Person Meeting"),
ordered = T),
Marital = factor(case_when(
Marital %in% c("Divorced", "Seperated", "Widowed", "Single") ~ "Single",
T ~ "Married")
),
Job = factor(case_when(
Job %in% c("Doctor", "Lawyer", "Teacher", "Engineer") ~ "Professional",
Job %in% c("Manager", "Salesperson", "Nurse") ~ "Employed",
Job %in% c("Artist", "Entrepreneur") ~ "SelfEmployed",
T ~ Job
)),
ComPref = factor(case_when(
ComPref %in% c("Mail", "Email", "Text") ~ "Written",
ComPref %in% c("Phone", "In-Person Meeting") ~ "Personal"
)),
Edu = factor(case_when(
Edu %in% c("Associate Degree", "Bachelor's Degree") ~ "College",
Edu %in% c("Master's Degree", "Doctorate") ~ "Grad",
T ~ "None"
), levels = c("None", "College", "Grad"), ordered = T),
Freq = round(Cover/Prem),
Lever = round(Income/Prem),
Age = cut(Age, quantile(Age), labels = F, include.lowest=T),
Geo = factor(Geo)
)