Introduction
There are times when a lot of things are happening in a retail environment which can make forecasting on all of them a real chore. If we’re fortunate there will be a nice smooth trend we can pick out with a low maintenance model like exponential smoothing (ETS).
However, if we need a low maintenance forecast and the interactions between different things happening like price and promotion are making it difficult then Vector Auto Regressive models (VARs) can help make sense of the situation.
VAR models tie different variables together into a single unified model and we may not even need to use any additional external inputs. This is important because if we have to provide future values it can take time, especially if assumptions change often.
By including causal variables directly in the model we can minimize wasted time there will be fewer values we need to anticipate. As an added bonus, where we have two way interactions say between price and traffic counts, the model will naturally capture that inter-relationship.
Let’s explore using a VAR model to forecast product sales.
Dataset
We will use the same data that we used in this article where we discussed ARIMA models. It is a small time series dataset available on Kaggle at https://www.kaggle.com/datasets/soumyadiptadas/products-sales-timeseries-data.
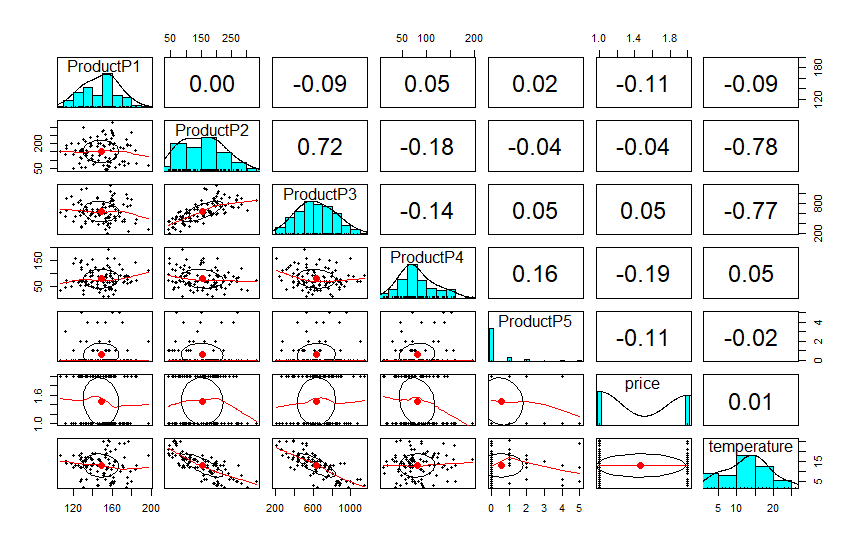
These data are a number of products that have inter-relationships plus price and temperature information. The data are very ill-behaved which makes it a great real world example.
Results
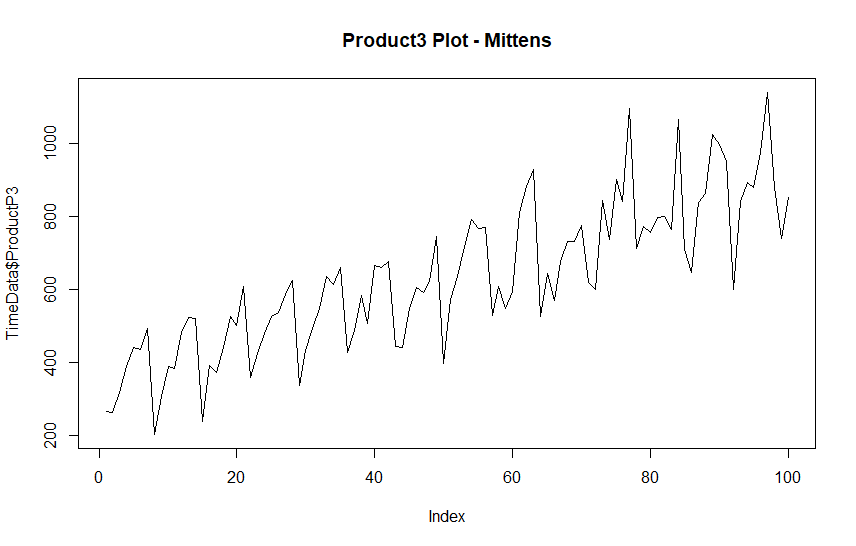
Creating a forecast allows us to make a short term prediction that we will sell 989 pairs of mittens three days from today, with a possible range between 400 and 1,500.
Follow along below in R Studio to see how we arrived at this result.
Exploratory Analysis
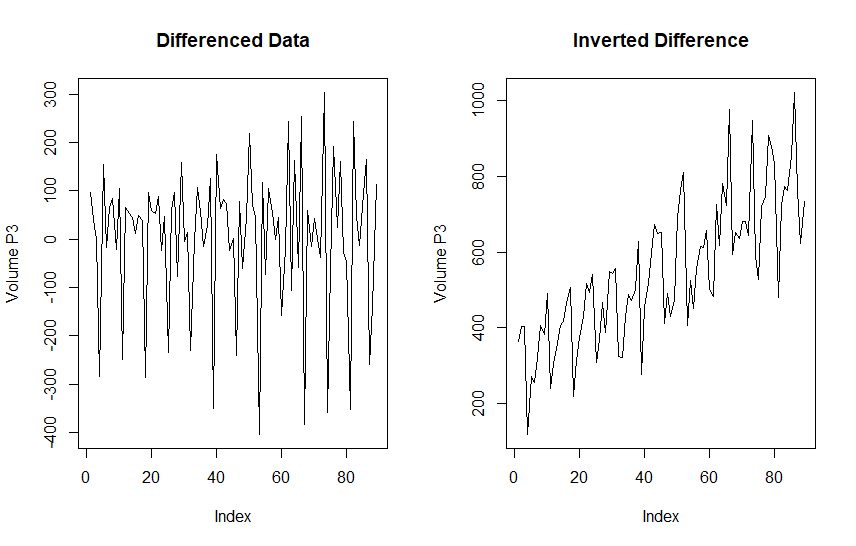
Our first step will be to load the 100 series observations and run summary statistics to identify any missing values. There are no missing values so imputation is not required.
Next we will run pairs.panels from the Psych package because it provides a great overview of any correlations within our category of products, plus the price and temperature variables.
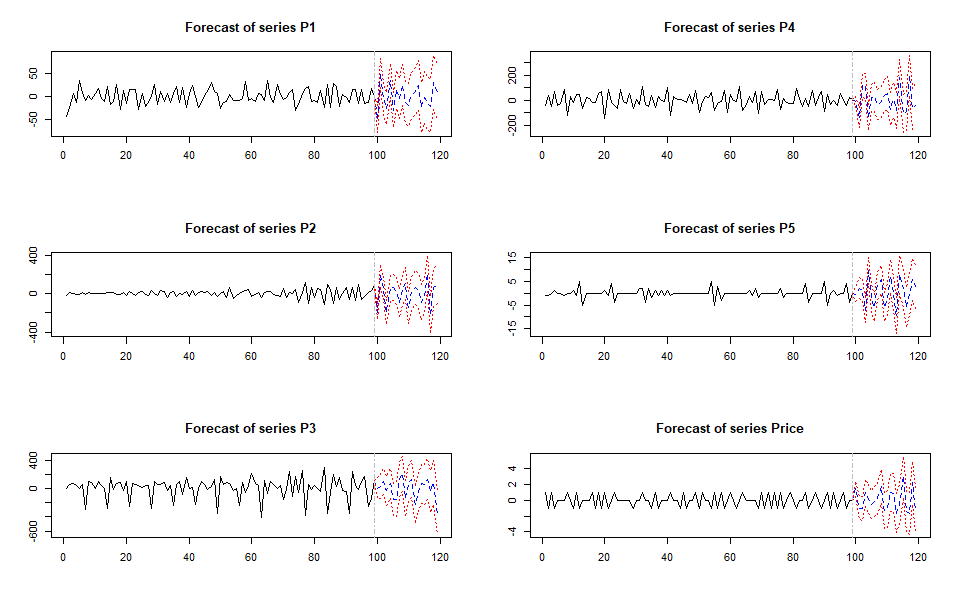
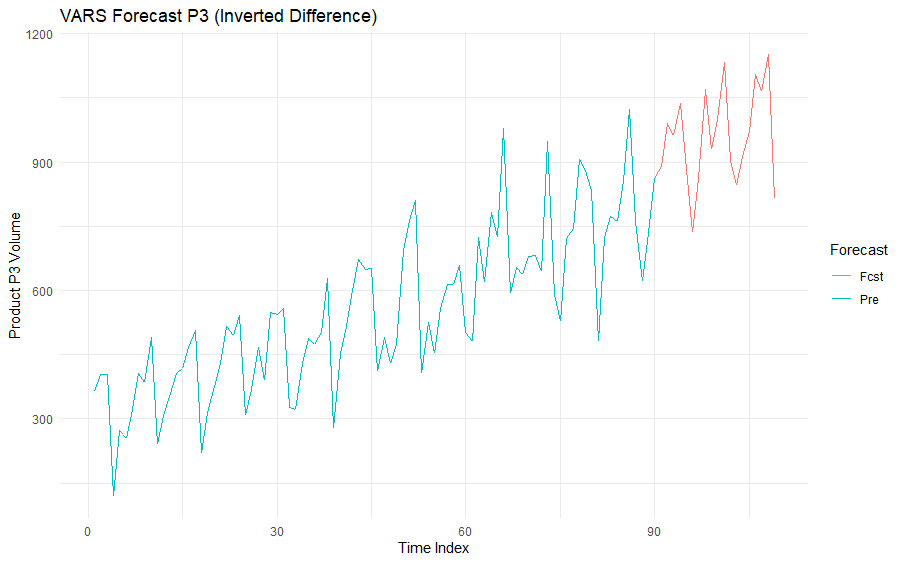
The forecast looks plausible, and from this point we could work on testing and if necessary tightening up some of the parameters.
As it stands, our forecast for three days from now would be 989 pairs of mittens, with a likely range between 400 and 1,500.
Prediction Confidence
The confidence bounds for this model are very large after a few periods, but we could easily run this forecast every day with a new seven day weather outlook.
For an autoregressive model it makes sense that there would be uncertainty for future periods. As we get farther away from the known data because each future observation depends on what comes before it, and eventually on the estimate of the estimate that came before it.
That doesn’t mean that our mitten sales will suddenly hit zero after 100 periods of growth, although that could happen with an early spring. Rather, it reflects the outer bounds model uncertainty due to declining information.
However, provided past patterns hold steady we would expect to see actuals that are reasonably close to the forecasted values and this type of model lends itself well to repeated, low maintenance, rolling forecasts which can be a very useful thing.
Conclusion
VAR models are popular in econometrics because they naturally handle a number of correlated variables that interact with each other. For the same reason they can be very useful in a retail context, particularly for co-dependent products.
They are often not a great choice for longer term forecasts but for short-term forecasts they can be very convenient options because they avoid the problem of having to provide future values. They can be auto-tuned easily, and simultaneously forecast all of the co-dependent variables.
Happy forecasting!
Ax=0